claude-mem-sync

claude-mem-sync turns
claude-mem’s single-developer memory into shared team knowledge.
It exports the AI memories that matter, merges and deduplicates them in a private Git repo, then
imports the merged set back into every developer’s localclaude-mem.db— with eviction scoring,
developer profiles, LLM-distilled rules and a dashboard. Git-native, privacy-first, zero servers.
In five minutes you’ll know exactly what this tool is, the problem it solves, why it beats every “just
copy the database” workaround, and where to click next. Every other page goes deeper — this one gives
you the whole picture.
What it is — in one minute
claude-mem gives Claude persistent memory across sessions, storing observations — decisions, bugfixes,
discoveries — in a local SQLite database. It’s brilliant, and it’s single-user, per-machine.
So on a real team, the knowledge never travels. Developer A discovers a critical pattern; developers B
through L never learn it. The same bug gets rediscovered. The same decision gets re-debated. There is
no native team mode, no shared database, no automatic sync.
claude-mem-sync closes that gap using Git as the transport layer:
- Export what matters — filter your local observations by type, keyword or tag, score them, and push
only the curated set to a private repo. Empty filters export nothing — you never leak by accident. - Merge in CI — a merge bot deduplicates across developers (composite-key, not auto-increment IDs),
caps the set with eviction scoring, and produces onemerged/latest.jsonper project. - Import back in — every developer pulls the merged set into their own
claude-mem.db, so Claude
picks up the whole team’s discoveries on the next session.
In one line: the team-memory layer
claude-memis missing — export, merge, dedup and import AI
memories across your whole team, over Git, with profiles and distilled rules on top.
The problem it solves
Every team that adopts claude-mem hits the same wall: memory is local, siloed and impossible to share
safely. Here is the gap this tool closes.
| Without claude-mem-sync | With claude-mem-sync |
|---|---|
| Each developer’s memory lives in their own SQLite DB — knowledge never crosses machines. | Curated observations sync across the team via a private Git repo and land in every local DB. |
Copying the whole .db around shares secrets, noise and another dev’s half-baked notes. |
Filtered export by type / keyword / tag shares only what matters; empty filters share nothing. |
| Twelve developers syncing weekly would bloat the DB into thousands of stale rows. | Eviction scoring + a per-project cap keep the merged set bounded; #keep protects the essentials. |
| Naïve merging duplicates the same memory once per developer. | Composite-key dedup (session + title + created_at) collapses duplicates across machines. |
| You have no idea which memories Claude actually uses. | A PostToolUse hook tracks real access, so used memories score higher and survive longer. |
| The team’s hard-won patterns stay locked in raw observations. | LLM distillation turns merged memories into CLAUDE.md-ready rules and a knowledge base (opt-in). |
| No visibility into who knows what or where the bus-factor risk is. | Developer profiles + a dashboard surface knowledge spectrum, concept gaps and contribution quality. |
Who it’s for
Already using claude-mem across a team? Point everyone at one private repo with their own devName and curated patterns flow to every machine — no shared server, no database surgery.
Laptop, desktop, work box — keep one curated memory set in sync everywhere through a private repo, instead of carrying a SQLite file around by hand.
Make Claude smarter for the whole team: the decisions and bugfixes one person teaches Claude become context every teammate’s Claude session can use.
Govern what gets shared with filters and PR review, surface knowledge gaps and bus-factor risk with profiles, and distill team rules — all from artifacts you own in your own repo.
Why it’s different — the moats
Most “memory sync” ideas are just copy the database and hope. This tool curates, scores, deduplicates
and governs — and never needs a server.
No server, no SaaS, no shared database to operate. A private Git repo is the transport — clone, push, pull. GitHub, GitLab and Bitbucket (incl. self-hosted) are all supported.
You share by type, keyword or tag (OR-combined). Empty filters export nothing by design — a safe default that makes accidental data leaks impossible, not just unlikely.
A scoring model (type × recency × access or diffusion) caps each project so the merged set never bloats. #keep pins critical memories with score = Infinity so they’re never pruned.
Duplicates collapse on a composite key (sdk_session_id + title + created_at), not the local auto-increment id — so the same memory exported by five devs becomes one row, every time.
A PostToolUse hook records which memories Claude actually reads, into a separate access.db that never touches claude-mem’s schema. Used memories score higher and outlive noise.
Export and the hook are read-only on claude-mem.db. Import is the only writer — wrapped in a transaction with rollback safety. Your source memory is never put at risk.
Deterministic per-dev metrics — knowledge spectrum, concept map, file coverage, temporal pattern, survival rate — plus team aggregates and bus-factor knowledge-gap detection. No LLM, no API spend.
Turn merged memories into CLAUDE.md-ready rules and a grouped knowledge base — double opt-in, delivered as a PR (never auto-merged), with no code, file paths or dev names in the output.
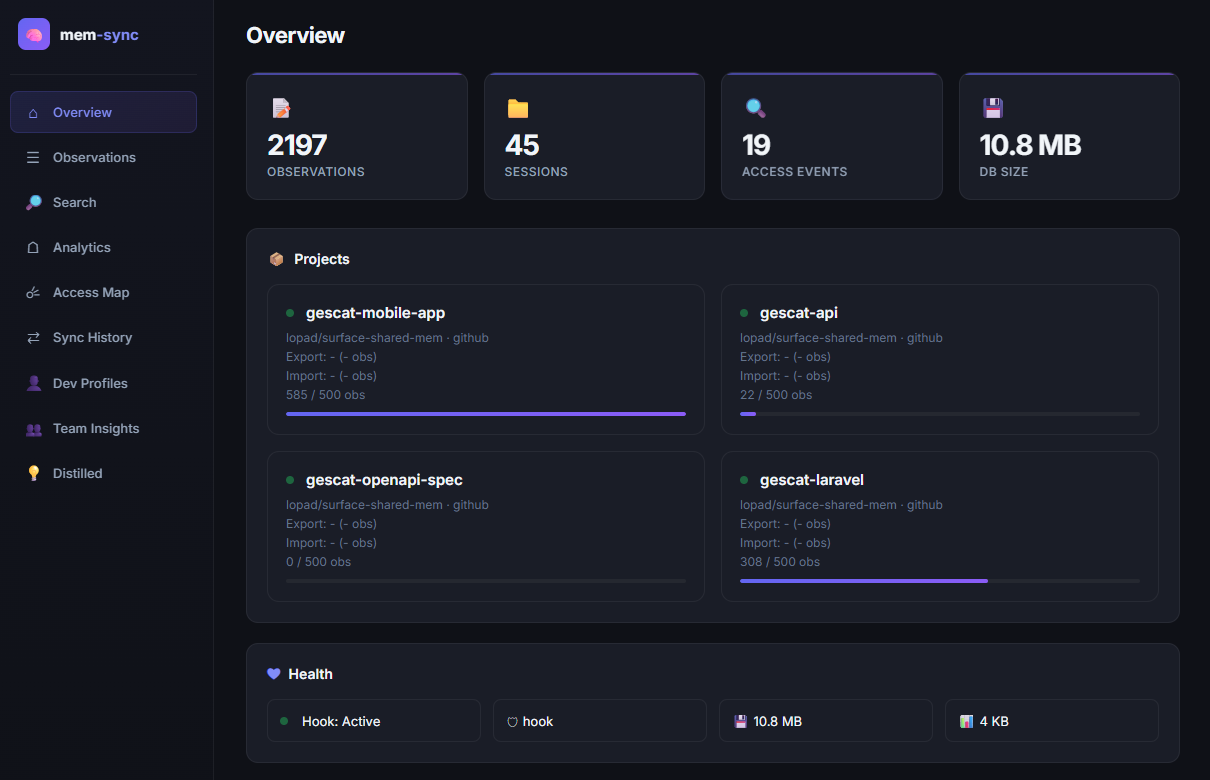
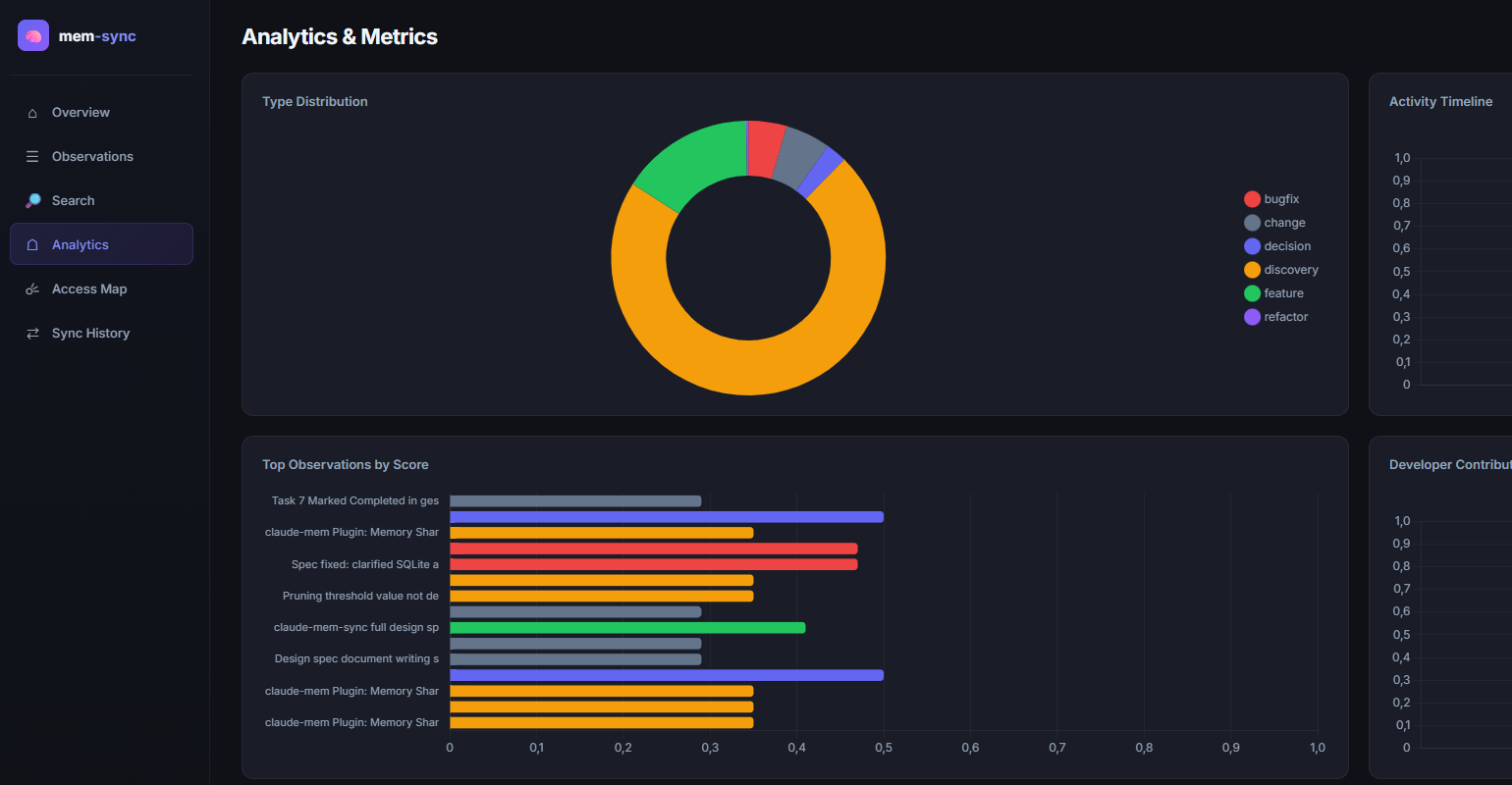
A 9-tab dark-theme SPA — overview, observations, search, analytics, access heatmap, sync history, profiles, team insights, distilled — served straight from your local DBs and repo artifacts.
See it
A local, zero-framework dashboard (mem-sync dashboard) visualizes everything — observations, access
patterns, developer profiles and distilled knowledge — read directly from your local databases.
claude-mem-sync vs. the alternatives
| Capability | claude-mem-sync | No sync (default claude-mem) | Copy the .db by hand |
Cloud “AI memory” SaaS |
|---|---|---|---|---|
| Share memories across a whole team | ✅ | ❌ | ➖ | ✅ |
| Filtered, never-leak export (type/keyword/tag) | ✅ | ❌ | ❌ | ➖ |
| Cross-machine dedup (composite key) | ✅ | ❌ | ❌ | ➖ |
| Eviction scoring + per-project cap | ✅ | ❌ | ❌ | ➖ |
| Real-usage access tracking (hook) | ✅ | ❌ | ❌ | ➖ |
| Developer profiles + knowledge-gap detection | ✅ | ❌ | ❌ | ➖ |
| Self-hosted, you own the data (private Git repo) | ✅ | ✅ | ✅ | ❌ |
| No server / no SaaS to operate | ✅ | ✅ | ✅ | ❌ |
Legend: ✅ built-in · ➖ partial / manual / not exposed · ❌ not available.
How it fits together
Each developer exports a filtered, scored slice to a private repo. A CI merge bot deduplicates and caps
it into one merged set, which everyone imports back — and which feeds profiles and distilled docs.
The eviction score that keeps the merged set bounded:
Start in 30 seconds
Install the plugin + CLI
claude plugin marketplace add lopadova/claude-mem-sync claude plugin install claude-mem-sync@claude-mem-syncThis installs the Claude Code plugin (the access-tracking hook) and the
mem-syncCLI globally.
Verify withmem-sync --help. (Requires Node ≥ 18 on yourPATH; Bun is recommended.)Run the setup wizard
mem-sync initPick your
devName, confirm yourclaude-mem.dbpath, and add a project pointing at a private
repo (owner/name) with your export filters.Preview, then export and import
mem-sync preview --project my-app # always preview first — confirm your filters mem-sync export --project my-app # push your curated slice mem-sync import --all # pull the team's merged memories back in
→ Quickstart · → Installation · → First Team Repository
Batteries included for AI-assisted development
This repo ships AI batteries — a CLAUDE.md working guide and an invocable .claude/skills/
docmd-docs skill encoding the house rules: read-only access to claude-mem’s DB, array-based command
execution (no shell injection), composite-key dedup, never-leak filter defaults and the docs-sync
discipline. Open the package in Claude Code, Cursor, Copilot or Codex and your agent already knows them.
Where to go next
Install, configure and run your first export/import in minutes. Open →
The theory behind filtered export, cross-machine dedup and the eviction-scoring model. Read →
The pipelines, the read-only invariants, and the ADRs behind the design. Explore →
npm @lopadova/claude-mem-sync · CLI mem-sync · Runtime Bun 1.0+ or Node ≥18 · MIT ·
GitHub ·
claude-mem
